library(tidyverse)
library(modeldata)
load("C:/BLOG/Workspaces/NIT Tutorial/NIT_ws1.RData")
ls()[1] "absorp" "endpoints" "tecator" First we load the libraries we are going to use, and the “workspace” from the previous post:
library(tidyverse)
library(modeldata)
load("C:/BLOG/Workspaces/NIT Tutorial/NIT_ws1.RData")
ls()[1] "absorp" "endpoints" "tecator" Now we can create another field called “SampleID” as a sequence from 1 to 215 (number of samples), it will be very usefull whenever we use the tecator dataframe:
tecator <- tecator %>%
rowid_to_column(var = "SampleID") The tecator data is available as well in the library “modeldata”, but with the name “meats”, so we can load it into the workspace and work with it using the tidyverse and tidymodels libraries. The idea of this tutorial is getting use to work with tidyverse and tidymodels at the same time that with classic R.
data(meats)The first 100 columns are the wavelengths are the datapoints and the last 3 the parameters, so we can rename de column names, and add an extra column called “SampleID” (same as row number).
colnames(meats) <- c(seq(850, 1048, by = 2), "Moisture", "Fat", "Protein")
meats <-
meats %>%
rowid_to_column(var = "SampleID")Now we can see the histograms with ggplot
meats %>%
ggplot(aes(Protein)) +
geom_histogram(bins = 20) +
ggtitle("Protein Meat histogram")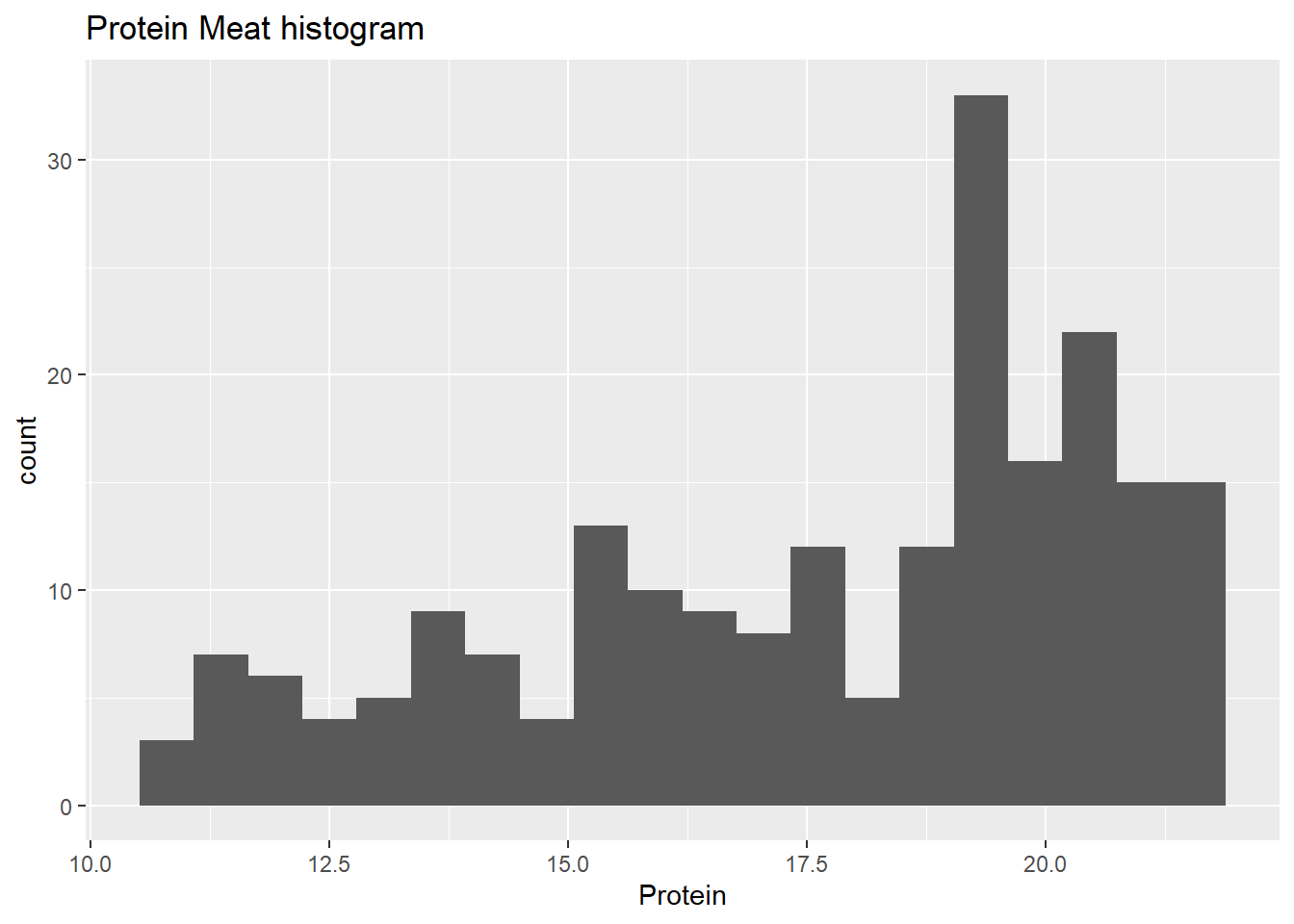
We can do the same for moisture and fat, but with some code we can see all the histograms at the same time:
meats %>%
select(SampleID, Moisture, Fat, Protein) %>%
pivot_longer(cols = Moisture:Protein,
names_to = "Parameter",
values_to = "Value") %>%
mutate(Parameter = as.factor(Parameter)) %>%
ggplot(aes(Value)) +
geom_histogram() +
facet_wrap(~ Parameter, scales = "free_x")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.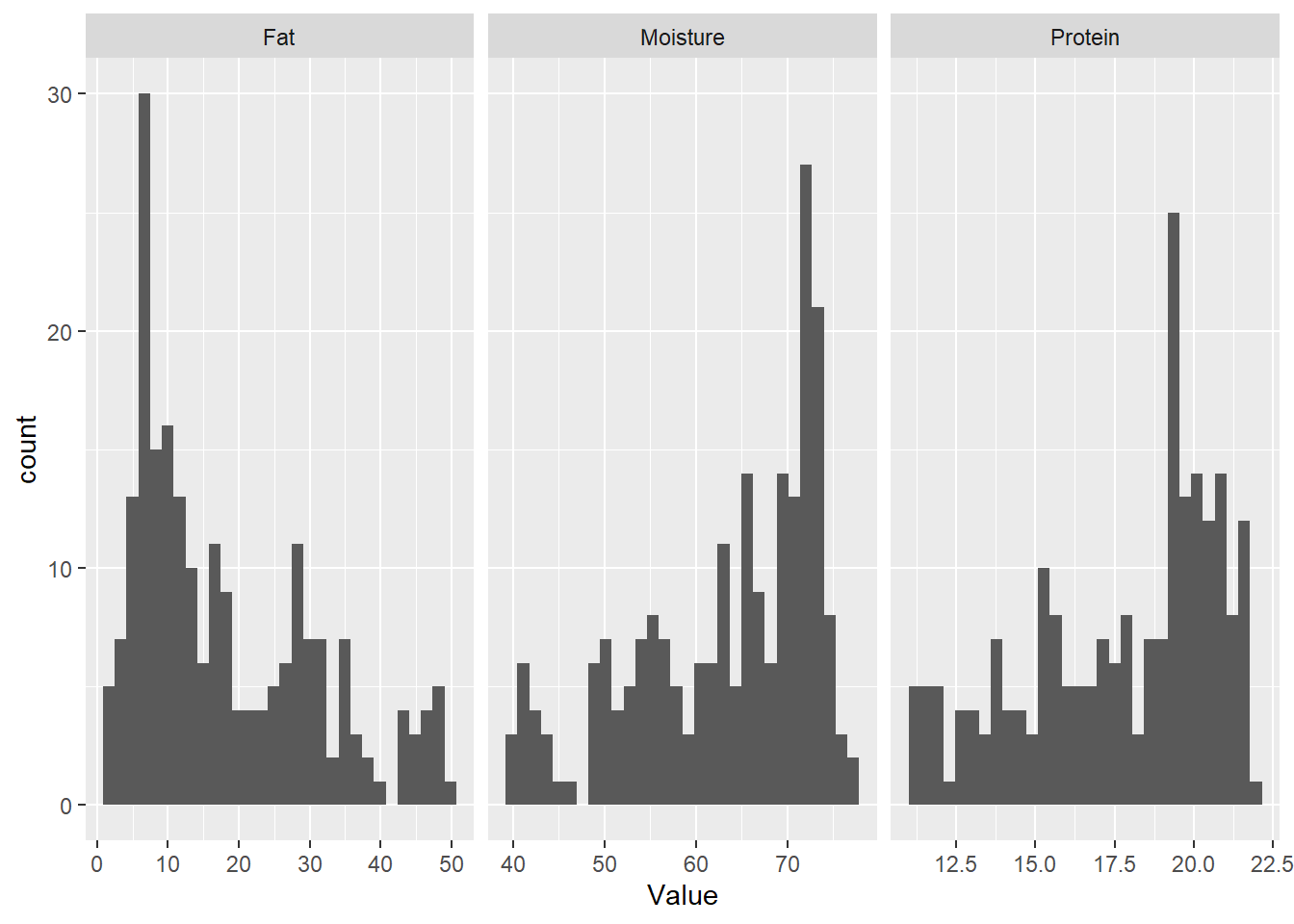
In order to see the spectra with ggplot we pivot longer meats data grouping by SampleID:
meats_longer <-
meats %>%
pivot_longer(cols = c(2:101),
names_to = "wavelength",
values_to = "absorbance") %>%
mutate(wavelength = as.integer(str_extract(wavelength, "[:digit:]+")))Save the workspace for future use
meats_longer %>%
ggplot(aes(x = wavelength, y = absorbance, group = SampleID)) +
geom_line(alpha = 0.5) +
theme_light()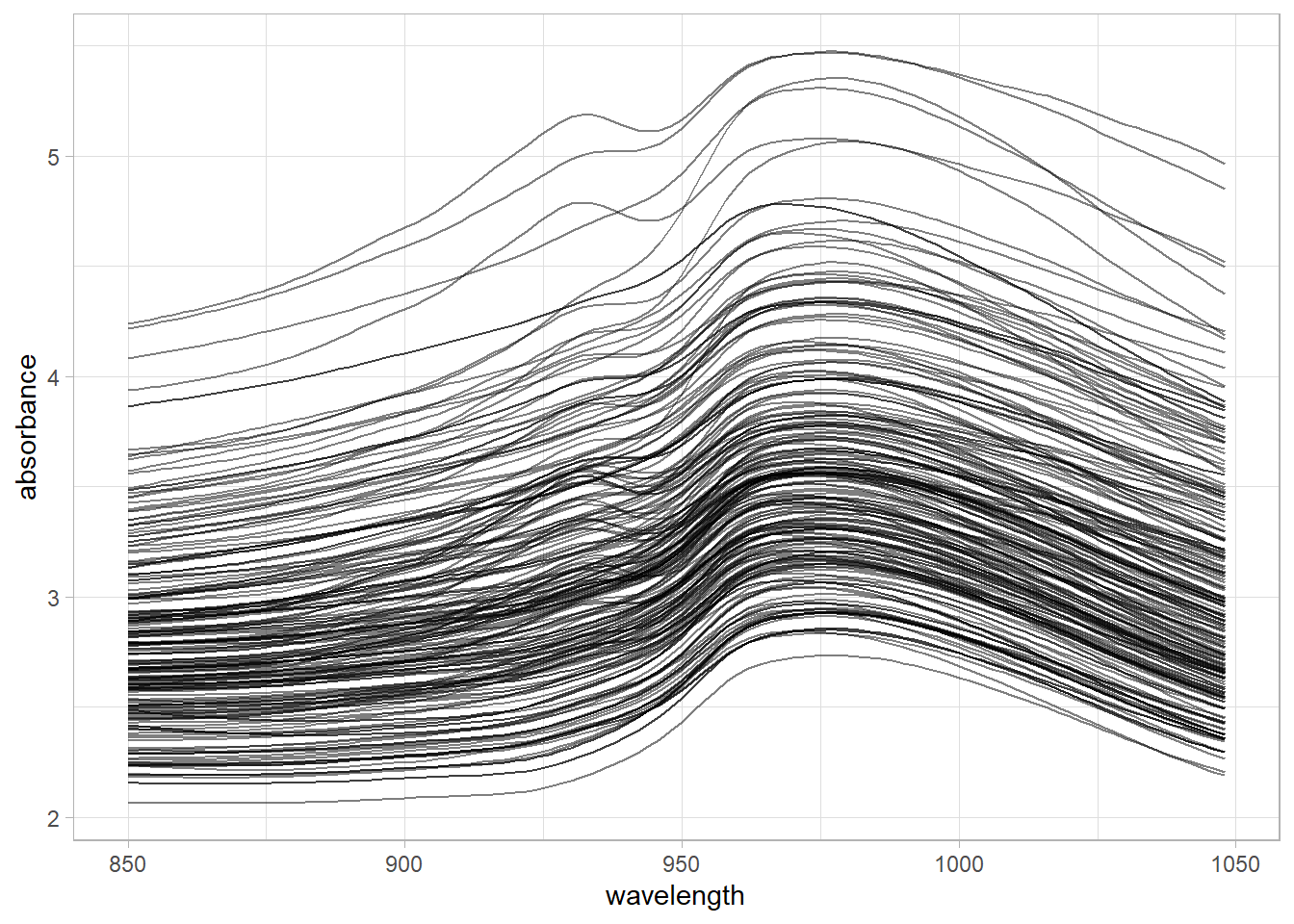
save.image("C:/BLOG/Workspaces/NIT Tutorial/NIT_ws2.RData")